Notes
Note
- These notes provide summaries of in-class lectures.
- They are not intended to replace the lectures (i.e., you still need to attend the lectures)
Syllabus
Administrative
- assignments
- 4-5 programming assignments (PA)
- 1 midterm, 1 final
- some small quizzes (Canvas, in class etc)
- communication: discussion via Canvas, email, office hrs (no TA)
(Implicit) Requirements
- you are familiar with Python or can quickly learn Python
- Able to install Python Jupyter's notebook and potentially some additional libraries
- Can install programs (e.g., for projects)
- Have your Python ready to run and try code
Testing & Verification & Program Analysis
- What is a bug?
- unexpected program behavior, (crash, incorrect outputs, assertion violation)
- consequence of bugs (security vulnerabilities, information leak, infinite loop, etc)
- Testing
- Find proof showing existing of bugs (or violation of some asserted properties)
- An algorithm that returns a witness show that the bug exist,
i.e., a test
- unit tests approach
- a fuzzer (what is it)
- a test input generation tool
- regression tests
- Examples: EvoSuite (Java), Java Pathfinder (model checking tool, NASA)
- Benefits
- fast (only consider a finite number of test)
- gives concrete inputs showing errors
- Disadvantages
- finding no bugs does not mean the software has no bugs
- Dijkstra: testing shows the existence of bugs, not its absense
- Could be slow or complex to setup (have to run the program)
- Verification
- Find proof showing the absense of bugs (or proof that some assertied properties always hold)
- an algorithm that shows a bug cannot exist
- a verification tool
- abstract interpretation tool
- Examples: Facebook Infer, Microsoft Blast, Astree (Airbus)
- Benefits (almost opposite to testing)
Intro to Testing
def my_sqrt(x):
"""Computes the square root of x, using the Newton-Raphson method"""
approx = None
guess = x / 2
while approx != guess:
approx = guess
guess = (approx + x / approx) / 2
return approx
- How to test this ?
- Unit test, assertion
assert my_sqrt(4) == 2assert abs(my_sqrt(x) - math.sqrt(x)) < EPSILON- Run the program on lots of tests
- test it on 100000 cases *run-time verification: integrate the assertion inside the code and run the test
- Testing is limited
- a div by 0 when input is 0
- an infinite loop when input is -1 (how do you check for \"infinite\" loop ? usually for testing, use timeout)
- Other kind of errors: invalid input format , e.g., input is
\"1\" instead of 1, but easy to fix (can write a wrapper, e.g.,
x = float(inp)) - Fuzzing techniques can help generating better, more diversify inputs
End of class on 8/18/2020 (https://unsat.github.io)
Compilation process
- Compiling/Interpreting gives the first defense to detect/prevent \"bad\" programs (e.g., those with syntax error, incorrect scoping or types)
Compilers and Interpreters
Two main approaches to implement programming languages are compilers and interpreters.
-
Examples of compilers and interpreter
-
Interpreter (On-line)
-
Input: a program and data
-
Output: an output, which is the result of running the program on the data
-
Compiler (Off-line)
-
Input: program
- Output: an executable, which is another program, written in another language (e.g., ASM, bytecode)
- We now can run this exe with some data, which produces some output.
- Off-line because we use the compiler as a preprocessing step to produce the exe, which can be run on many inputs.
Language Implementations
- Low level/System languages are compiled: C/C++
- \"Higher level\" are often interpreted: Python, Ruby, Javascript
- Some provide both: JAVA (JIT copmiler)
Brief History
IBM 704 in the 1950s
- Problem Software cost > hardware cost (which already costs a lot)
- How to write better software?
John Backus
- Speedcoding: early from of interpreter
- Advantages: much faster to develop programs, more productivty for programmers
- Disadvantages:
- slow: (10 - 20x slower than programs written in lower level, same as today, interpreted programs are slow comparing to compiled programs)
- space: take up more space (300 bytes, which is 30% of the memory of the IBM 704)
- Did not become so popular, but lead to another invention by Backus
Fortran 1
- Back then, most important apps are scientific computations which involve lots of formulas
- translating formulas to machine code would make these computation faster
- hence, formula translation: FORTRAN
- 1954 - 1957: 3 years to build this translator or compiler for Fortran
- 1958: 50% of all code written in Fortran: a new technology.
- Huge success: raised the level of abstraction (programmers write in high-level language), increase productivity, etc
- Lead to lots of work on both theory and practice
- Not possible to design PL/compilers without deep theory
- Not possible to create good compilers without good engineering/building skills
Structures of compilers
- Still use the same one used by FORTRAN 1
-
The five phases of compilers
-
Lexical Analysis (Syntax)
- Parsing (Syntax)
- Semantic Analysis (Semantics)
- Optimization (transformation on the program to make it run faster or uses less memory)
- Code Generation (translates to another language, e.g., machine code, bytecode, or even another high-level language)
Understanding the five phases of compilers
- Analogy to how human understand English
- Example
- Understanding a program : understanding the words
"This is a sentence.": human see 4 words- There are some hidden computation here: e.g., have to recognize the separators (blnak), punctuation (period), capital letters.
- These help divide/classify this group of letters.
Lexical Analysis
- Goal: divide program text into words, or token
if x==y then z=1; else z=2;- tokens are keywords (if, then, else), variable names (x,y,z), constants/ditis (1,2), operators (==, =), others (;, blank) .
- How do we know we should use == or = ?
- How do we know if something is a digit ? e.g., is 12 a digit ? is 1.2 a digit ? is 1a2 a digit ?
- Answer: We use Finite Automata to recognize these.
Parser
-
Lexical Analysis can help recognize/classify text into tokens using FA.
-
Next we want to know whether these tokens together form a \"valid\" program, i.e., if together they have a valid structures.
-
This line is a longer sentence -
Back to English grammar, lex analysis can tell if something like \"this, thast, a\" is an article, \"line, sentence\" is nounce. But it doesn\'t tell if the structure of the sentence is correct.
-
another example
if x = y then z = 1; else z = 2 ; -
FA itself is quite limited, can tell that 2 is an int/const, x,y are vars, but cannot tell if this whole thing is correct.
-
In fact, it can't even about the
matching parenthensisproblem, which is used frequently in programming (Context Free Grammar) -
Need something more powerful, this is when the parsing task comes in.
-
Compilers uses parsing (which takes as input results of lex analysis) to tell if a program is valid (or has some syntax error)
- Lots of works in this domain, we\'ll spend a chunk of time on this, but not too much since nowadays we no longer need to worry too much about parsing
Semantics Analysis
-
Once we have a valid program, we can try to understand what it means !!!
-
This is hard -
Compiler performs very limited semantic analysis to catch inconsistencies
-
Example:
Jack said Jerry left his assignment at home. -
Even worse:
Jack said Jack left his assignment at home? -
Programming languages have rules to avoid ambiguities
{
int Jack = 3;
{
int Jack = 4;
cout << Jack;
}
}
-
Typing:
-
Also perform other semantic checks
- Example:
Jack left her homework at home. - A "type mismatch" between her and Jack (assume Jack is a guy); we know they are different people
Optimization
-
Optimization has no strong counterpart in English
-
But a little bit like editing. Same meaning, but shorter, easier to understand
-
Automatically modify programs so that they -
-
Run faster
- Use less memory
-
Use less power
-
But unlike natural language, compiler has to be very precise, it really has to preserve the semantics, i.e., the new program has to behave the same as the old one.
-
Example
X = Y * 0 is the same as X = 0? -
No! only true for integers, not true for floating points, NaN * 0 = NaN
Code Generation
- Produce Assembly code (usually)
- Essentially a translation from a language to another (just like how human does it)
Classical vs Modern Compilers
- Every compiler has these five phases, but their proportions have changed over the years
- In the past [ l ] [ p ] [s] [ o ] [ cg ]: lots of focus on parsing
- Now [l][p] [ s ] [ o ] [ cg ]: mostly optimization
Imperative vs Functional
- Imperative: change state, assignments
- Structured: if/block/routine control flow, while/for loop
-
Function: functions are first-class citizens that can be passed around or called recursively. We can avoid changing state by passing copies
-
Pattern matching, recursive call
::: {.CENTER} End of class on 8/20/2020 :::
Topic: Random Testing (Fuzzing)
History
- Fall 1988, Barton Miller at UWisconsin, connecting to his university computer
- Thunderstorm caused noise on the tel line, causing the UNIX commands on both computers to get bad inputs, and crash
- Miller: Programs are NOT very robust, give exercise for his students on testing this theory: the first fuzzer
- \"The goal of this project is to evaluate the robustness of various UNIX utility programs, given an unpredictable input stream. [...] First, you will build a fuzz generator. This is a program that will output a random character stream. Second, you will take the fuzz generator and use it to attack as many UNIX utilities as possible, with the goal of trying to break them.\"
A simpler Fuzzer in Python
import random
def fuzzer(max_length=100, char_start=32, char_range=32):
"""A string of up to `max_length` characters
in the range [`char_start`, `char_start` + `char_range`]"""
string_length = random.randrange(0, max_length + 1)
out = ""
for i in range(0, string_length):
out += chr(random.randrange(char_start, char_start + char_range))
return out
- can write these random string to file and feed it to Unix commands,
e.g.,
bc(basic calculator) - can create a loop and keep doing this
- In 1989, MIller and his students using these simple fuzzer found that a third of Unix utilities they fuzzed have issues: crashed, hung, failed (of course, most of these bugs are now fixed).
Buffer Overflow
- Programs in C often have built-in max lengths for inputs, using inputs excessing these lengths could trigger the buffer overflows .
char weekday[9]; // 8 characters + trailing '\0' terminator
strcpy (weekday, input); // e.g., "Wednesday",
- the \'y\' and \'\0\' (string terminator) are copied to whatever resides in memory after weekday, triggering arbitrary behavior.
- we want to create a check to ensure the length are within range (and raise Exception if it does not)
Uncommon values
```
char *read_input() {
size_t size = read_buffer_size();
char *buffer = (char *)malloc(size);
// fill buffer
return (buffer);
}
```
Potential issues: size too lage, exceeding program memory, size is
not large enough (buff overflow), size is neg ?
HeartBleed
- security bug in OpenSSL library (ecryption implementation providing secured communication over network, e.g., browser, transaction)
- Leaking information
- due to out-of-bounds access to memory
- https://xkcd.com/1354/
- How was it discovered:
- Reserachers at Codenomicon and Google compiled OpenSSL library with memory sanitizer and load it with fuzzed command and the sanitizer reports out-of-bounds access error
OptionBleed
Catching Errors
- Manually put in checking code (e.g., if (size > ...) exit )
- Design/Use a safer language (Rust, Java)
- Program Analysis tool (e.g., LLVM address Sanitizer detects a whole set of potentially dnagerous memory safety violation, built into C compiler CLANG)
- But these kind of checkings slow down execution quit a big (AddressAnitizer 2X) and consume more memory (but still worth it to catch bugs)
- RepOK code (e.g., ensure that input is a tree, after operation, output still a tree)
- Static checker (e.g., type checker for lang like Python)
Other kinds of testing techniques
Regression Testing
- \"I swear I have seen and fixed this bug before\"
- May be, but someone else broke it again in the new version of the code
- a regression in the source code
<!-- -->
- Best practice: after fixing a bug, add a test that specifically exposes that bug (regression test) to ensure future implementation still fix the issue
Unit Testing
- Wikipedia: unit testing is a software testing method by which individual units of source code---sets of one or more computer program modules together with associated control data, usage procedures, and operating procedures---are tested to determine whether they are fit for use
- Test cases "look like other code"
- They are special methods written to return a boolean or raise assertion failures
- advantage iosolation: tests for Individual function, module, parts ..., when a test fail, easy to locate bug; advantage small/fast : test are small and run fast
Integration Testing
- Things work in isolation, what happens if they are put together ? (e.g., each player is ready, but do they well well as the whole team ?)
- Integration testing: combines and tests individual software modules as a group
Mock Objects
- "Mock objects are simulated objects that mimic the behavior of real objects in controlled ways."
- In testing, mocking uses a mock object to test the behavior of some other object.
- Analogy: use a crash test dummy instead of real human to test automobiles
- Example: working on something, but depends on something not being done yet (or very expensive) , what to do: create a mock (fake) object to simulate that
Combinatory Testing
End of class on 8/24/2020
Code Coverage
- We learn basic fuzzing, e.g., generating random tests/inputs, in previous class. But how do we measure the effectiveness of the tests?
- Can measure the number of bugs (.e.g, crash, inf loop, incorrect output) found
- But bugs are rare, so we want to have some metrics or proxy for the likelihood of a test to uncover a bug
- One such metrics is code coverage, which measures which parts of the program were executed when running the program on a test.
- The goal of most test generators is to cover as much code as possible.
An example: CGI decoder
#include <stdlib.h>
#include <string.h>
#include <stdio.h>
int hex_values[256];
void init_hex_values() {
for (int i = 0; i < sizeof(hex_values) / sizeof(int); i++) {
hex_values[i] = -1;
}
hex_values['0'] = 0; hex_values['1'] = 1; hex_values['2'] = 2; hex_values['3'] = 3;
hex_values['4'] = 4; hex_values['5'] = 5; hex_values['6'] = 6; hex_values['7'] = 7;
hex_values['8'] = 8; hex_values['9'] = 9;
hex_values['a'] = 10; hex_values['b'] = 11; hex_values['c'] = 12; hex_values['d'] = 13;
hex_values['e'] = 14; hex_values['f'] = 15;
hex_values['A'] = 10; hex_values['B'] = 11; hex_values['C'] = 12; hex_values['D'] = 13;
hex_values['E'] = 14; hex_values['F'] = 15;
}
int cgi_decode(char *s, char *t) {
while (*s != '\0') {
if (*s == '+')
*t++ = ' ';
else if (*s == '%') {
int digit_high = *++s;
int digit_low = *++s;
if (hex_values[digit_high] >= 0 && hex_values[digit_low] >= 0) {
*t++ = hex_values[digit_high] * 16 + hex_values[digit_low];
}
else
return -1;
}
else
*t++ = *s;
s++;
}
*t = '\0';
return 0;
}
int main(int argc, char *argv[]) {
init_hex_values();
if (argc >= 2) {
char *s = argv[1];
char *t = malloc(strlen(s) + 1); /* output is at most as long as input */
int ret = cgi_decode(s, t);
printf("%s\n", t);
return ret;
}
else
{
printf("cgi_decode: usage: cgi_decode STRING\n");
return 1;
}
}
- CGI decoder:
- used to decode a CGI-encoded string
- used in URL\'s to encode characters that would be invalid
- Blanks are replaced by \'+\'
- invalid chars are replaced by \'%xx\', where xx is the two-digit hexdecmical equivalent
- Example \"Hello, world!\" becomes \"Hello%2c+world%21\"
where
2cand21are the hexadecimal equivalents of \',\' and \'!\', respectively.
- CGI decoder takes as input a CGI-encoded string (e.g., url) and
decode it back to the original form
- \"Hello%2c+world%21\" becomes \"Hello, world!\"
- Q: How can we want to test the
cgi_decodefunction - using black-box and white-box testing
Blackbox Testing
- generate tests from the specification, domain knowledge, document
-
For CGI decoder, we would test
-
correct replacement of \'+\', \"%xx\", non-replacement of other characters, testing for recognition of illegal inputs
$ ./cgi '+' # should give ' ' $ ./cgi "%20" # should give ' ' $ ./cgi "abc" # should give abc $ ./cgi "%?a" # give some error -
Advantage: can find errors in the specified behavior; can create special cases tests (according to the specs); indepdent of implementation (can create tests even before implementation)
- Disadvantage: the implementation contains more details (can potential bugs) that are not specified. Need to test those
Whitebox Testing
- generate tests from the implementation, the internal structure. E.g., want to have tests that makes the program to execute all of its statements.
- Statement/Line coverage is frequently used in whitebox testing
Statement/Line coverage
- each stmt in the code must be executed by at least one test input
- Informal: visiting more lines is better because you have no information about un-visited lines.
-
Can be used as a metrics to compare testsuite: prefer testsuite that covers more line (use this to guide software testing process, generate a testsuite with high coverage)
-
Code Coverage example
-
One nice thing about whitebox testing is we can automatically assess whether some program statements were covered.
-
Instrument stmts in code, record/count executed statements (that we have not yet seen previously), show results to programmer to test for hard-to-reach statements.
-
Coverage tool:
- instrumentation modifies a program to record coverage information in a way that minimizes effect (not slowing down too much)
- This can be done at the source or binary level. Don\'t actually print to stdout/stderr
- Don\'t slow things down too much
- Pre-check before printing a duplicate?
-
This is a \"solved\" problem, almost every lang has a good coverage tool (gcc\'s
gcov, Python\'scoverage, etc) -
Example
bash $ gcc --coverage -o cgi cgi.c $ ./cgi 'Send+mail+to+me%40unl.edu' $ gcov cgi.c $ less cgi.c.gcov - So with such coverage tool (Python, Java, .. etc all have such tools), we can write a loop that keep fuzzing inputs to test the programs to try to get as many statements covered as possible (for cgi, takes about 40-60 fuzzing inputs).
Branch coverage
-
Statement coverage can be insufficient, can you think of a case when you have 100\% line coverage but still get bugs?
-
Branch coverage
-
each branch ... (if/while guards : once being true/once being false)
-
For the cgi example, we want to test all the ite/while blocks
-
Advantage: find errors in impelmented behavior; find corner cases
-
Disadvantages: might miss non-implemented behavior (e.g., specification ones)
-
Example:
foo(a): if a != 0: x = 100/a print(x) -
Test Suite
foo(7)has 100% line coverage but 50% branch coverage. -
Test Suite
foo(7), foo(0)has 100% line and 100% branch coverage. -
In general branch coverage implies line coverage. BC also gives more confidence than line coverage.
-
But, BC is harder to achieve comparing to LC
-
Other type of coverage metrics: function coverage, # of times loops iterate, data flow btw variable def\'s ...
Mutating Inputs
-
Let's say we want to test a web browser where the input is a URL (which has a specific format
scheme://netloc/path?query#fragment -
scheme is the protocol to be used, including http, https, ftp, file...
-
netloc is the name of the host to connect to, such as www.google.com
-
path is the path on that very host, such as search
-
query is a list of key/value pairs, such as q=fuzzing
-
fragment is a marker for a location in the retrieved document, such as #result
-
Then the fuzzing technique we learn don\'t really work, because it just generate randomly stuff that unlikely fit this format, i.e., the chance of generating a valid URL is almost 0
-
So instead of generating random string from scratch. We start with a valid input, and then mutate it to generate new (andlikely) valid input.
-
Mutation in this context simply means manipulating the string
- inserting a random char
- deleting a char
- flipping / switching ...
- This is call mutational fuzzing
Code example
import random
def delete_random_character(s):
"""Returns s with a random character deleted"""
if s == "":
return s
pos = random.randint(0, len(s) - 1)
# print("Deleting", repr(s[pos]), "at", pos)
return s[:pos] + s[pos + 1:]
def insert_random_character(s):
"""Returns s with a random character inserted"""
pos = random.randint(0, len(s))
random_character = chr(random.randrange(32, 127))
# print("Inserting", repr(random_character), "at", pos)
return s[:pos] + random_character + s[pos:]
def flip_random_character(s):
"""Returns s with a random bit flipped in a random position"""
if s == "":
return s
pos = random.randint(0, len(s) - 1)
c = s[pos]
bit = 1 << random.randint(0, 6)
new_c = chr(ord(c) ^ bit)
# print("Flipping", bit, "in", repr(c) + ", giving", repr(new_c))
return s[:pos] + new_c + s[pos + 1:]
def mutate(s):
"""Return s with a random mutation applied"""
mutators = [
delete_random_character,
insert_random_character,
flip_random_character
]
mutator = random.choice(mutators)
# print(mutator)
return mutator(s)
# apply mutation once
for i in range(10):
print(repr(mutate("A quick brown fox")))
# apply mutation multiple times
seed_input = "http://www.google.com/search?q=fuzzing"
mutations = 50
inp = seed_input
for i in range(mutations):
if i % 5 == 0:
print(i, "mutations:", repr(inp))
inp = mutate(inp)
AFL (American Fuzzy Lop)
- leverage coverage to generate \"smarter\" inputs
- Guide by input having new coverage
End of class R 8/27/2020
Announcement:
- Programming Assignment 1 is out (due in 1 week)
- Covers (Greybox Fuzzing) technique
Graybox Fuzzing
Recall
- Blackbox fuzzing: not implementation specific, generate test based on domain knowledge that is independent of the implementation (in fact can be done before writing the program)
- Whitebox fuzzing: implementation specific, generate tests specific for the implementation
- Line/Statement coverage
-
Usually heavy-weight program anlaysis (e.g., constraint solving based)
-
AFL is a form of graybox fuzzing
-
Not blackbox because it uses coverage-feedback to try to explore more code
-
Not whitebox either because is relatively lightweight (just coverage instrumentation)
-
Today we'll talk a bit more about Graybox fuzzing techniques
- In addition to just favoring inputs with high code coverage, we might also prefer inputs that give "unusual" path that are not exercised very frequently
- Boosted Graybox fuzzing
Bosted Graybox Fuzzing / Power Schedules
- favor input seeds maximizing some goals
- energy: likely hood that an input in a population being chosen for fuzzing
- schedule: assign energy to seed inputs (higher energy to those likely maximize the goal)
- AFL's schedule: more energy to seeds that are shorter, run faster, and increase coverage.
- Exponential schedule for unusual path: more energy to seeds that exercised unusual paths, e.g.,
e(s) = 1/f(p(s))^a
Live Example: Fuzzing book (GreyFuzzing chapter)
def crashme (s):
if len(s) > 0 and s[0] == 'b':
if len(s) > 1 and s[1] == 'a':
if len(s) > 2 and s[2] == 'd':
if len(s) > 3 and s[3] == '!':
raise Exception()
- quite difficult to get to this
Exceptionlocation with pure Blackbox fuzzing - if we start with some seed, e.g., "good", also equally bad, only hit the first
ifline - what about Greybox fuzzing ?
Another Live Example: Python HTML parser (GreyFuzzing chapter)
Targeted Fuzzing
- Aims to hit particular location
- Needs to compute the distance to that location. How?
- Using the Control Flow Graph (CFG) as an estimate.
Live Example: Control Flow Graph
- see example in Fuzzing book (ControlFlowGraph chapter)
Search-Based Fuzzing
- Generalization of Targeted Fuzzing and all the graybox fuzzing metrics we covered
- Sometimes, we are not interested in generating as maany as possible diversed inputs, but specific inputs that achieve some object (e.g., reaching a specific statement)
- This is a classical search problem in CS
- often associated with these search problem are Breadth or Depth First Search
- But these are unrealistic as too many possible inputs
- Domain knowledge can help
- E.g., if we know among many inputs, where ones are more "preferred", then we can use this information to help the search
- This guidance/information is called a heuristic
- The way we apply a heuristic systematically in an algorithm is called a "meta-heuristic" search algorithm (meta here means these algorithms are generic and instantiated differently for diff algs)
- Often inspired from nature
- Darwin's evolutionary process
- swarm intelligence (ant's, bee's)
End of class T 9/1/2020
Search Space
- the space of potential solutions we are looking for
- For our input generation problem, the search space are the set of potential inputs
- More specifically, if we have a program that takes as input 3 integers, then the search space for that program is the set of tuple of size 3
Fitness
- assign a fitness to candidate solution
- Low or high: depend on the problem and your preference
Code instrument to obtain fitness
Two types of Search Algorithms
- Local Search, e.g., Hillclimbing, works well when the neighborhood is well defined and not too large.
- Global Search, e.g., Genetic Algorithm, is very flexible and scale up well to larger problems.
Hilclimbing: Local search
- simplest possible meta-heuristic algorithm.
- The algorithm tries to climb a hill (or descending into a valley) in the search space defined by our representation.
-
The algorithm
-
Take a random starting point
- Determine fitness value of all neighbours
- Move to neighbour with the better fitness value
-
If solution is not found, continue with step 2
-
Common Problems/Tweaks (depends on the problem):
- Restrict the search space (e.g., setting the search values to be within some range, e.g., -1000, 1000)
- Steepest Ascent Hillclimbing
- evaluate all neighbors and choose the best one (really greedy)
- Local Optima: stuck at a local optimum point, cannot find anything better
- a potential solution: Random restart
Limitations of Hill climbing
- Only works for perfect landscape, e.g., one of the neighbors has better fitness and we can keep following better neighbor to reach the optimal sol
-
In practice, many problems do not have such perfect lanscape. Moreover, they might have much more complex and larger landscape.
Live Code demo
- Code example 1
def test_me(x, y):
if x == 2 * (y + 1):
return True
else:
return False
- Neighbors: for an input
x,y, we have 8 neighbors:x+1,y,x,y+1,x+1,y+1,x-1,y,x,y-1,x-1,y-1,x-1,y+1,x+1,y-1 -
Range restriction:
MAX=1000 , MIN=-MAX -
Code example 2: the CGI decoding program we have been using
Global Search Algorithms
- Instead of looking at all the immediate neighbours, the individual is mutated in a way that allows larger modifications.
-
Mutation design
-
Should be able to get to any point in the search space by applying mutation successively
- should not complete replace an individual (still want to maintain most of its traits)
-
E.g.,given a string, a potential mutation is to just randomly replace one of the char with a random char
-
Randomized hilclimbing algorithm/(1+1)EA
- Just like hillclimbing but with mutation
- At each iteration, the current individual is mtuated, and the one with highest fitness are chosen for the next iteration
- Also called 1+1 EA:
- An evolutionary algorithm that mimic natural process of evolution: fittest survive
- 1+1 means: population of 1 individual and produce exactly 1 off-spring
Genetic Algorithms
- A solution candidate is called an
individualorchromosome, e.g.,astringor1,23,-1 - Each chromesome consists of a sequence of genes
- Fitness function takeas as input an individual or chromosome, then evaluate the fitness (wrt to the problem)
- Algorithm:
- Create an initial population of random chromosomes
- Select fit individuals for reproduction
- Generate new population through reproduction of selected individuals
- Continue doing so until an optimal solution has been found, or some other limit has been reached.
The representation
- Problem dependent
- Very important (and tricky) part of designing a GA
Creating Population
- a set of say 1000 randomly generated solution
Fitness function
- Problem dependent
- Also extremely important: the success of the GA depends on this !
Selection
- Roulette Wheel
- Tournament Selection
Genetic Operation
- Crossover:
- 1-point crossover
- Exploitation, try to maintain the genes of the parents
- Gradual change
- Mutation:
- 1-point mutation
- Exploration
- Drastical change
End of class R 9/3/2020
Iteration
- In the beginning: exploitation rate is high and exploration state is low
- After a while (especially when hitting local optima), exploration increases , explotation decreases
- After getting out of local optima, reset so that exploitation becomes high again
Stopping Criteria
- When hitting the optimal fitness (but in many cases, we don't know whether that is possible)
- Hit certain threshold (good enough)
- After certain number of unchanged iterations (generation)
Presentation: Automatic Program Repair using Genetic Algorithm
PA1 due tonight !
End of class T 9/8/2020
Topic: Mutation Testing
- Coverage, which identifies which parts of the program are executed, gives a sense of the effectiveness of test cases.
- But, good coverage is not always effective
- Today we introduce another way of testing the effectiveness of testsuites: mutation testing
- The idea is injecting mutations (or aritificial faults) into code and check if the test suite can detect the faults. (if it fails to detect such mutation, it might also miss real bugs)
Motivation: Coverage is not enough to compare testsuites
def triangle(a, b, c):
if a == b:
if b == c:
return 'Equilateral'
else:
return 'Isosceles'
else:
if b == c:
return "Isosceles"
else:
if a == c:
return "Isosceles"
else:
return "Scalene"
Consider two testsuites below: strong oracle and weak oracle
assert triangle(1, 1, 1) == 'Equilateral'
assert triangle(1, 2, 1) == 'Isosceles'
assert triangle(2, 2, 1) == 'Isosceles'
assert triangle(1, 2, 2) == 'Isosceles'
assert triangle(1, 2, 3) == 'Scalene'
assert triangle(1, 1, 1) == 'Equilateral'
assert triangle(1, 2, 1) != 'Equilateral'
assert triangle(2, 2, 1) != 'Equilateral'
assert triangle(1, 2, 2) != 'Equilateral'
assert triangle(1, 2, 3) != 'Equilateral'
triaglepasses both tessuites, so what does this mean? should we be confident ? only if the testsuite are good enough.- Q: But are these testsuites good ? Which one is better ?
- strong oracle is better ... but how do you know ?
- Coverage is not enough
- both testsuite cover the same number lines (demo). So absolutely no difference in coverage.
- The problem is coverage does not consider the quality of the assertions ... it doesn't care about the expected behavior encoded in the tests
- We need a way to incorporate these assertions in tests
Mutation Testing: How to test your tests !
- What is the goal of testing?
- To find bugs!
- So we can test the effectiveness of the tesuite by finding bugs.
- How do we get these bugs?
- fault injection:We inject them to the program!
def triangle_m1(a, b, c):
if a == b:
if b == c:
return 'Equilateral'
else:
# return 'Isosceles'
return None # <-- injected fault
else:
if b == c:
return "Isosceles"
else:
if a == c:
return "Isosceles"
else:
return "Scalene"
- In the above program (where we injected a bug),
weak oraclestill pass, butstrong oraclefails and hence detects the bug! - So we want to do this, but we want a systematic way to do this (to avoid manual work which is expensive and also biased): Mutation Analysis
Mutation Analysis
- Based on two hypotheses.
- Competent programmer hypothesis: that most software faults introduced by experienced programmers are due to small syntactic errors
- coupling effect: simple faults can cascade or couple to form other emergent faults
Mutating Code: (DEMO)
- program represented as an AST
- Mutate nodes in the tree
-
Traditional mutation operators
-
Delete statement
- Statement duplication or insertion
- Replacement of boolean subexpressions with true and false
- Replacement of some arithmetic operations with others, e.g. + with *, - with /
- Replacement of some boolean relations with others, e.g. > with >=, == and <=
-
Replacement of variables with others from the same scope (variable types must be compatible) There are other operators designed for OO languages, security testing, etc ..
-
Each mutated program is called a mutant
Evaluating Mutation (DEMO)
triangle-
gcd -
live mutants: not detected by the code (e.g., because the mutation doesn't change behavior (more later)) or the test is inadequate
-
dead mutants: detected by the tests
- mutation score = number of mutants killed (detected) / total number of mutants
Equivalent Mutations: a big problem in Mutation Analysis
Several kinds of mutants:
- Useful ones: behave differently in the original program and cannot be detected by our test (thus shows th weakness of our tests that we can improve)
- Stillborn mutants: Syntactically incorrect, killed by compiler , e.g.,
x = a ++ b - Trivial mutants: Killed by almost any test case
- Equivalent mutant: same behavior as the original program, e.g.,
x = a + bandx = a – (-b)
def gcd(a, b):
if a < b:
a, b = b, a
else:
a, b = a, b
while b != 0:
a, b = b, a % b
return a
def gcd_mutant1(a, b):
if a < b:
a, b = b, a
else:
pass
while b != 0:
a, b = b, a % b
return a
- What is the problem here ?
- Equivalent Mutant:
gcd_mutantis a mutant, but is equivalent togcd, so it will never be "killed". If we generate a lot of such mutants, then we gill give a "false" mutation score to the testsuite. - How to detect equivalent mutants, i.e., check program equivalence: theoretically undecidable and generally very hard.
Pros/Cons
-
Advantages
-
Powerful approach to attain high coverage of the source program (a side benefit ! also get high coverage)
- Cmprehensively testing the mutant program.
- Brings a good level of error detection
-
Uncovers ambiguities in the source code and has the capacity to detect all the faults in the program.
-
Disadvantages
- Costly and time-consuming (many mutant programs that need to be generated).
- Needs good automation tool (luckily many existed for most popular languages)
- As this method involves source code changes, it is not at all applicable for Black Box Testing.
End of class R 9/10/2020
Recall
- Learn how to fuzz/randomly generate inputs
- random mutation
- AFL-style on mutation and iteration to generate inputs
- Genetic Algorithm / Hill Climbing
- High Coverage
- Mutation Testing (geneting mutants from programs as a metrics to rank/compare test suites)
- All of these : 1st section of the Fuzzing book
Input languages
- Inputs to the program control the behaviors of the program
- Input here can be various things: e.g., input params to the program, data read from files, environment, network, etc ..
- For simplicity, let's just stick to input prams directly given to the program or function (e.g., the
xinfoo(x)) - The set of valid inputs to a program is the language of that program
- language can range from simple to complex
- simple: an integer (e.g., a program that takes an intger as input), CSV , etc
- complex: a program itself (a compiler is a program that takes a program as input)
- Intuitively, every different format is its own "language" (csv, html, python, java, etc)
- Wikpedia lists more than 1000 different file formats and thus 1000 diff languages: https://en.wikipedia.org/wiki/List_of_file_formats
Formal Languages (RE & CFG)
- The field/study of Formal Languages defines a number of language specifications to describe a language
- Regular Expression
- used to describe "simple" languages
- An RE describes a set of strings that are member of some language (or class)
- Example: The RE
[a-z]denotes the (possibily empty) set of lowercase letters , the RE{0,1,2...,9}the set of 10 digits, .. - We use RE regularly to describe the class of things
- in English: the RE for color
{green,black,blue,white,yellow ...}, noun, verb, ... - in Programming:
- Variable names (identifier): set of string of letters or digits, starting with letter
a1, x, y, B17 - Integers: non-empty string of digits
0,12, 001, 3 - Keywords:
if, else, try, except(for Python) - White space: a non-empty seq of blanks, newlines, and tabs
- These classes are called "tokens"
- Variable names (identifier): set of string of letters or digits, starting with letter
- Lexer: 1st phase of Compiler:
- lexical analysis -> take a program, and a set of rules (i.e., regular expressions), scan every single char in that program, break/classifiy them into
tokensbased on the RE's - when you write some program and run it, the compiler (or interpreter) say something about invalid syntax, e.g.,
iff... how does it know ? it's due to this phase (iff is not recognized by any regular expression) - RE has 5 constructs
- single char
c = {'c'}, epsilone = {''}, concatAB(A,B are RE's), unionA + B, iterationA^* , A^iA^0 = e - Can also be represented using Finite automata
- an RE <=> an FA
- Summary: an RE/FA represents a set of strings (so given a string, it can check if that string is a member of that set (accept) or reject)
Context Free Grammar
- parser: input (tokens from LA) and a set of rules
- set of rules = grammar (Context Free Grammar (CFG))
(1 + 2: pass lexical analysis, but will not pass parsing, #'s left paren match #'s # right paren ...- nested structure
if then else
parse input string into a tree (using the provided CFG)
Derivation Tree
if x == y then 1 else 2 fi
if-then-else
/ | \
==
/ \ int (1) int(2)
id (x) id (y)
CFG:
- Good for defining recursive grammar and structure
- Expr:
if Expr then Expr else Expr fi => if (if ...) then (if) .... - CFG
- a set of terminals T
- a set of non-terminals N
- a start symbols s (member of N)
- a set of production (rules)
- x -> y1, ... , y n (x is a nonterminal, y non-term, terminal, {e})
CFG for
- balance parenthesis (only accept when having balance parens, e.g., '', () , ((())) , .. ) . Reject '(' , '())' ...
CFG:
S -> (S)
S -> e
S is a non-terminal
e is empty char ''
(), (((S))) ...
CFG for EXPR
EXPR -> if (EXPR) then (EXPR) else (EXPR) fi
EXPR -> id
if (id) then (id) else (id) fi (if x then y else z fi)
if (if (EXPR) then (id) else id) then (EXPR) else (EXPR) fi ...
Derivation Tree comes in (parser takes input string -> derivation tree )
CFG for expression , accept string such as id + id , id * ((id * (id + id))) ...
E -> E + E | E * E | (E) | id
id * id + id
E -> E + E -> E _ E + E -> id _ E + E -> id _ id + E -> id _ id + id
Parse tree 1 for id * id + id
E
E + E
E * E id
id id
Parse tree 2 for id * id + id
E
E * E
id E + E
id id
Ambiguity
- has multiple derivation trees
- generally bad: which tree to use to evaluate ?
End of class T 9/15/2020
Grammar-based Fuzzing
- CFG examples
- Digits from 00 to 99
- Integers
- Arithmetic Expression
-
Demo: using Python to represent CFG
-
0-9
-
Expr
-
Parser vs Generator
-
Parser (Recognizer): given as input a string, create derivation tree to check if that string conforms to a grammar
- Compilers/Interpreter/Web browsers are prime examples
- Efficient parsing algorithm is an important topic in CS (e.g., how to do it quickly, how to avoid deal with ambiguity, how to deal with error, etc)
- In practice, there are many existing parsers we can reuse
- Generator: given a grammar, creates strings conforming to that grammar
- Used to generate test inputs (e.g., to test compilers/web browsers)
-
We'll learn how to do a grammar-based inputs generator today
-
Generator
-
Given a CFG, the fuzzer simply start with the
<start>symbol and keeps on expanding it. - Use a max limit on the number of
non-terminalsto restrict the size of the expr - Also limit the number of expansion steps
- Demo: Expr
- Demo: Natural Language (Book Title)
- Demo: URL
-
Demo: using grammar-based fuzzed inputs as starting seeds (URL CFG)
-
More advanced ideas in creating Generator
- Instead of using the simple string based fuzzer like described, we can use Derivation trees
- much more efficient (e.g., can define depth of trees to stop expansion)
- Goal based:
- Just like what we learn with traditional fuzzing, we can modify the grammar-based fuzzer to generate test inputs to maximize some goals
- in grammar based testing, the goal can be
- test every non-terminal symbols at least once
- test every terminal symbol at least once
- test every rules in the grammar at least once
- Mutation testing:
- Just as with normal mutation, we can also apply mutation to grammar-based fuzzer
- We can treat the inputs as trees (e.g., a program can be represented as a tree) and design operators over the tree (e.g., GenProg's style)
Uses of grammar-based testing
- to test compilers and Web browsers
- CSmith 2011: uses C grammar to generate valid C code to test compilers (found over 400 compiler bugs)
- LangFuzz 2012 (authors of the fuzzing book): generate JavaScripts programs to test browsers (found over 2,600 bugs in Firefox, Chrome, and Edge)
- EMI 2014: found thousand of bugs in GCC,LLVM
End of class R 9/17/2020
Topic: Delta Debugging (Minimizing Inputs)
- Resources: this topic is very popular and there are many resources to learn more about it: Fuzzingbook, Youtube, Google, etc
Needs an oracle to tell whether the input fails or pass
Motiv example
1999, Bugzilla (Mozilla / Firefox)
- When I open this website, Firefox crashes
- Mozzila BUGAThon
- Look for volunteers to SIMPLIFY the bug reports
- Mozilla BugAThon call: "When you’ve cut away as much HTML, CSS, and JavaScript as you can, and cutting away any more causes the bug to disappear, you’re done."
- For example, we want to reduce this
<td align=left valign=top>
<SELECT NAME="op sys" MULTIPLE SIZE=7>
<OPTION VALUE="All">All<OPTION VALUE="Windows 3.1">Windows 3.1<OPTION VALUE="Windows 95">Windows 95<OPTION VALUE="Windows 98">Windows 98<OPTION VALUE="Windows ME">Windows ME<OPTION VALUE="Windows 2000">Windows 2000<OPTION VALUE="Windows NT">Windows NT<OPTION VALUE="Mac System 7">Mac System 7<OPTION VALUE="Mac System 7.5">Mac System 7.5<OPTION VALUE="Mac System 7.6.1">Mac System 7.6.1<OPTION VALUE="Mac System 8.0">
Mac System 8.0<OPTION VALUE="Mac System 8.5">Mac System 8.5<OPTION VALUE="Mac System 8.6">Mac System 8.6<OPTION VALUE="Mac System 9.x">Mac System 9.x<OPTION VALUE="MacOS X">MacOS X<OPTION VALUE="Linux">Linux<OPTION VALUE="BSDI">BSDI<OPTION VALUE="FreeBSD">FreeBSD<OPTION VALUE="NetBSD">NetBSD<OPTION VALUE="OpenBSD">OpenBSD<OPTION VALUE="AIX">AIX<OPTION VALUE="BeOS">BeOS<OPTION VALUE="HP-UX">HP-UX<OPTION VALUE="IRIX">IRIX<OPTION VALUE="Neutrino">Neutrino<OPTION VALUE="OpenVMS">OpenVMS<OPTION VALUE="OS/2">OS/2<OPTION VALUE="OSF/1">OSF/1<OPTION VALUE="Solaris">Solaris<OPTION VALUE="SunOS">SunOS<OPTION VALUE="other">other</SELECT>
</td>
<td align=left valign=top>
<SELECT NAME="priority" MULTIPLE SIZE=7>
<OPTION VALUE="--">--<OPTION VALUE="P1">P1<OPTION VALUE="P2">P2<OPTION VALUE="P3">P3<OPTION VALUE="P4">P4<OPTION VALUE="P5">P5</SELECT>
</td>
<td align=left valign=top>
<SELECT NAME="bug severity" MULTIPLE SIZE=7>
<OPTION VALUE="blocker">blocker<OPTION VALUE="critical">critical<OPTION VALUE="major">major<OPTION VALUE="normal">normal<OPTION VALUE="minor">minor<OPTION VALUE="trivial">trivial<OPTION VALUE="enhancement">enhancement</SELECT>
</tr>
</table>
to this
<select></select>
DELTA DEBUGGING
- The problem: reducing (crashing) inputs as much as possible (but still retains the crash)
- Delta Debugging: starting with the original failure input, cut it into parts and test each part, if a part fails, we can focus on it.
1. <SELECT NAME="priority" MULTIPLE SIZE=7> : F
n=2
2. <SELECT NAME="priority : P
3. " MULTIPLE SIZE=7> : P
n = 4
<SELECT NAME ="priority " MULTIPLE SIZE=7>
4.<SELECT NAME ="priority " MULTIPLE : P
5.<SELECT NAME ="priority SIZE=7> : F
6. ........
30. <SELECT> : F
31. <SEL : P
32. ECT> : P
.... : P
...
40 ....
<SELECT>
- Many examples on Delta Debugging being used in the real world.
- GCC: Run Delta on the C program that crashes the GCC (compiler) to obtain a minimal C' program that still crashes GCC
- Determine run-time options (e.g., turn this option on and that option off gives some interesting behaviors)
In Class Assignment
1. abcdef*h : anything that has * causes a failure
2. *abcdef* : anything that has both ** causes a failure
End of class T 9/22/2020
Review: Delta Debugging
- Example: program failed when input contains ** (both)
*abcdef* : F
n = 2 *abc / def*
def* : P (remove 1st part)
*abc : P (remove 2nd part)
n = 4 *a/bc/de/f*
bcdef* : P (remove 1st part)
*adef* : F (remove 2nd part, WORKS, was able to eliminate bc from *abcdef* )
n = 2 *ad/ef*
ef* : P
*ad : P
n = 4 *a/de/f/* (or can split like */a/de/f*)
def* : P
*af* : F (remove 2nd part, WORKS, was able eliminate de from *adef*)
n = 2 *a/f*
f* : P
*a : P
n = 4 */a/f*/
af* : P
*f* : F (remove 2nd part , WORKS, elim a from *af*)
n =2 *f/*
* : P
*f : P
n = 3 */f/*
f* : P
** : F (elim f from *f*)
n = 2 */*
* : P
* : P
STOP, Answer: **
Statistical Debugging
def median(x, y, z):
print("input ", x, y, z) #1
m = z #2
if y < z: #3
if x < y: #4
m = y #5
elif x < z: #6
m = y #7 BUG
else: #8
if x > y: #9
m = z #10 BUG
elif x > z: #11
m = x #12
print("result", m)
Test median(1,2,3) = 2 median(1,3,2) = 2 ....
Tarantula Technique
Score(s) = #bad tests hitting(s) / # of bad tests
-----------------------------------------------------------------------------------
#bad tests hitting(s) / # of bad tests + # good tests hitting(s) / # of good test
-
Suspicious socre of statement
-
(4/4) / (4/4 + 6/6) = 0.5
- ...
- ...
- ...
- ...
- ...
- (2/4) / (2/4 + 2/6) = 0.60
- ...
- ..
-
(2/4) / (2/4 + 1/6) = 0.75
-
here's the Python code if you're interested
def alg_Tarantula(good_nruns, good_occurs, bad_nruns, bad_occurs):
a = float(bad_occurs) / bad_nruns
b = float(good_occurs) / good_nruns
c = a + b
return a / c if c else 0.0
End of class R 9/24/2020
Topic: Specifications & Constraint Solving
-
Assertion:
-
e.g.,
assert(x >= y),assert (0<=i <= len(L)-1,assert(sorted(array),assert (is_binary_tree(t)),assert (p != NULL)- How do you assert program terminate?
- predicate, boolean formula
- encoding of expected property at certain program location
- If a property or an assertion p is always true at a loc l, then p is the invariant at l
- Invariant Locations
- At the end of a function/method/program: postcondition
- At the loop entrance: loop invairants
- Program Specification:
- Precondition (assume)
- Postcondition(assert)
- Correctness
- Partial (assume termination) vs Total (needs to also show the program terminates)
- Safety property
- An assertion indicating "safetyness", e.g., index accessing within range
- no division by zero
- encode these property as assertion in code
- assertion violation: problem
-
Goal is to if an assertion p always hold at some loc l, i.e., p is invariant at l
- True: it is
- False: it is not, in this case needs to return an input showing its violation
- Example
int foo1(int x,int y): int z = 0 if (2*x == y): if (42 <= y && y <= 45): z == 1 assert(z==0);-
assert(z==0) is FALSE in foo1
- x = 21 , y = 42
-
Another Example
int foo2(int x,int y): int z = 0 if (2*x == y && x + y == 10): if (42 <= y && y <= 45): z == 1 assert(z==0);assert(z==0)is TRUE in foo1- no inputs can violate this assertion
-
CONSTRAINT SOLVING
- Given a formula, want to know if it is satisfiable or not
- formula
- evaluates to True or False
- involve variables
- if variables have domain 2 (true/false, 0,1)
- Satisability problem (3-SAT is NP-Complete)
- Sat formula
- Solvable using a SAT solver
- if variables have infinite domain (e.g., integers, and thus formulas can be involve arithmetic expressions)
2*x == y and 42 <=y and y <= 452*x == y and x + y == 10 && 42 <=y and y <= 45- SMT formula
- Solvable using an SMT solver
Complexity Zoo
-
Complexity classes of problem (i.e., how "difficult" it is to solve these problems)
-
Worst case complexity,
big Onotation O(c): Constant time , e.g., is 1+3 == 4O(log n): Logarithmic, does x exist in a sorted list of size n?O(n): Linear time, e.g., is a given list of size n sorted, does x exist in an (unsorted) list ?- Decision problem: YES OR NO
O(n log n): (merge) sort a given listO (n^2): bubble sortO (n^3): Equation solving (Gaussian), (naiv) Multiplication of 2 matrices- ... all polynomial
-
O (2^n): exponential time (is a given SAT formula true?)- 3-SAT
- Does there exist a better algorithm ? We don't know. Likely note, NP-Complete
- NP-Complete: easy to check, hard to solve
- Scheduling: assigning university classes to timeslot to minimize scheduling conflicts
- Assigning wedding guests to seats so that friends sit at the same table , but enemies do not
- a road trip to visit all tourist spot on a list, but minimize driving
- parallel parking ?
- Soduko
- Every NPC problem can be transformed to another (in polynomial time), i.e., if you can find a polytime alg for one NPC problem, you solve the whole class
-
O(2^2^n): doubly exponential (is a given SMT formula (integers, but without multiplication) true) -
UNDECIDABLE:- is a given SMT formula (integers with multiplication, Presburger arith) true
- First-Order logic
- does this program halt?
- is P an invariant at location L?
End of class T 9/29/2020
SMT Solving
- Constraint solver
- SAT formulae
- FoL formulae
- Z3 SMT Solver (Microsoft Research)
- Python code illustration
Symbolic Execution
int foo(int i){
// i = 1
// i = i_input
// i_input = -1
int j = 2*i;
// i=1, j=2
// i = i_input, j=2*i_input
// j = - 2
i = i++;
// i = 2, j =2
// i = i_input + 1 , j = 2*i_input
// i = 0
i = i*j;
// i = 4, j = 2
// i = (i_input+1) * (2*i_input)
// i = 0
if (i < 1){
// (i_input+1) * (2*i_input) < 1
i = -i ;
// i = -((i_input+1) * (2*i_input)) && (i_input+1) * (2*i_input) < 1 (then branch)
}
else{
// !((i_input+1) * (2*i_input) < 1) = (i_input+1) * (2*i_input) >= 1 (else branch)
//==
// i =(i_input+1) * (2*i_input) && (i_input+1) * (2*i_input) >= 1
}
//i = -((i_input+1) * (2*i_input)) && (i_input+1) * (2*i_input) < 1 then branch
//OR
//i =(i_input+1) * (2*i_input) && (i_input+1) * (2*i_input) >= 1
return i;
}
- Concrete execution
i=1,- Symbolic execution
i= i_input
int foo(i){
....
assert(p);
}
// convert into
int foo(i){
....
if (!p){
//assertion violation
//use symbolic execution to obtain a formula HERE
error()
}
}
-
Tree Representation
-
Symexe Tree
- Simulate program execution over symbolic input values
- Path condition
- Feasible vs Infeasible Paths
-
Example:
def foo(a,b,c): # give symbolic values (capitalized letter) to inputs: # a = A, b = B, c = C x = 0, y = 0, z = 0 if (a!=0): x = - 2 if (b < 5): if (a==0 and c!=0): y = 1 z = 2 } assert (x+y+z != 3) #equiv to #if (x+y+z == 3): # raise Exception #assertion violation
x=0,y=0,z=0
|
A!=0
t/ \f
x=-2 B<5
| t/ \f
B < 5 A==0 &&C!=0 path 6
t/ \f t/ \f
A==0 && C!=0 path 3 y=1 z=2
t/ \f | |
y=1 z=2 z=2 path 5
| | |
z=2 path 2 path 4
|
path 1
For each path: - path condition - feasible ? - inputs (that would take the program onto that path) - local variables - does it violate the given assertion
Path 1, A!=0 && B < 5 && (A == 0 && C!=0) , INFEASIBLE (b/c path cond is UNSAT),
Path 2, A!=0 && B < 5 && !(A==0 && C !=0) , FEASIBLE , A=1, B=4, C=1, (x=-2, y=0, z=2), NO ERR
Path 3
Path 4, !(A!=0) && B < 5 && A==0 && C !=0, FEASIBLE, A=0,B=0,C=1, (x=0, y=1, z=2), ERROR (ASSERTION VIOATION)
Path 5
Path 6
-
Applications
-
Test generation (use Z3 to generate inputs allowing to reach some location)
- Find bugs (representing assert(p) as if (!p) {//bug})
- Check if two programs are equiv, e.g.,
p==q
int foo(x){....return y;}
int bar(x){....return z;}
int check(x){
assert(foo(x) == bar(x));
//if (foo(x) != bar(x)){//NOT EQUIV}
}
3 Challenges of Symbolic Execution
Difficulty in modelling programs
- system calls (e.g., malloc, open)
- Library calls:
sin,glibc, - Pointers and heap: linked list, tree, etc
- Loops and recursive calls: how to provide a good summary of loops/recursive calls
Constraint solver might not be powerful enough
- NP-Complete in general, i.e., can be slow
- Not expressive enough (e.g., have hardtime dealing with nonlinear arithmetics, string, quantifiers, disjunction)
Path Explosion (sequential conditional stmts and loops)
nsequential if-then-else : symbolic execution tree of2^npaths
foo( ...)
if(x1){
}
else{
}
if(x2){
}
else{
}
...
....
if(xn){
}
else{
}
- Things become more complicated when dealing with loops
x=0
while(x < n){
x++;
}
..
// =>
if(x < n){
x++
}
else{
..
}
if(x < n)
..
if(x < n){
x++
}
else{
..
}
if(x < n){
x++
}
else{
..
if(x < n){
x++
}
else{
..
End of class R 10/1/2020 and T 10/7/2020
Delta Debugging Review
abcdef : fail whenever input contains abcdef
n=2 abc/def
def : P abc: P
n=4 a/bc/d/ef bcdef : P adef : P abcef : P abcd : P
n = 6 a/b/c/d/e/f
bcdef : P acdef : P abdef :P abcef : P abcdf : P abcde :P
return abcdef : fail
14 times O(2n) ~ O(n) <= Not the worst case
best case: O(log n)
==========
Come up with a concrete example showing worst case of DD
input = abcdef oracle: fail when the input is exactly "abcdef" OR "abcde" OR "abce" ...
O(N^2)
2N + 2(N-1) + 2(N-2) ... = 2N(N+1) / 2 = 2N^2 + 2N = O(N^2)
n=2 abc/def
def : P abc: P
n=4 a/bc/d/ef bcdef : P adef : P abcef : P abcd : P
n = 6 a/b/c/d/e/f
bcdef : P acdef : P abdef :P abcef : P abcdf : P abcde : F
start with abcde
n = 2 ab/cde cde : P ab : P
n = 4 a/b/c/de bcde : P acde : P abde : P abc: P
n=5 a/b/c/d/e bcde : P acde : P abde : P abce: F
start with abce
...
...
Midterm review & exam
PA4: Symbolic Execution & DNN
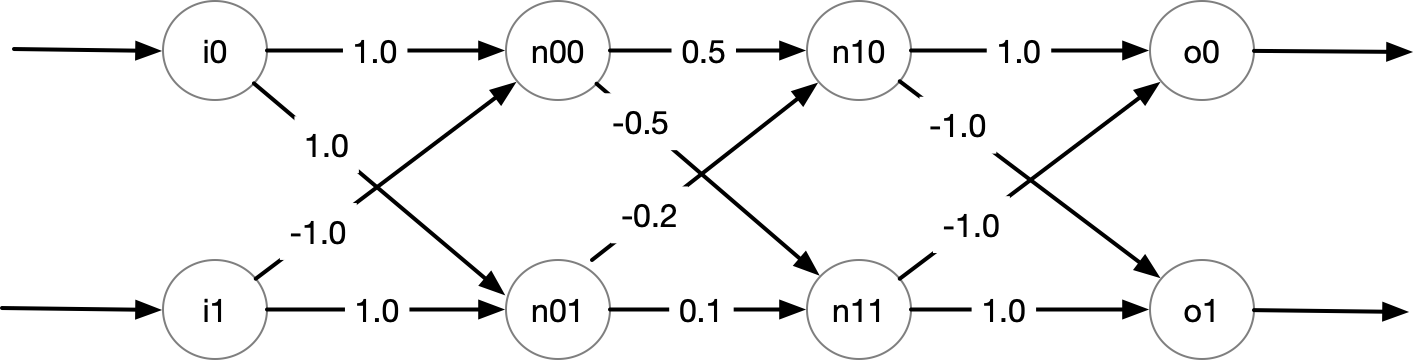
def mydnn(i0, i1):
n00 = (i0 * 1.0) + (i1* -1.0)
if n00 > 0:
n00_ = n00
else:
n00_ = 0
# n00 = relu(n00) # if then else
n01 = (i0 * 1.0) + (i1* 1.0)
n01 = relu(n01) # if then else
n11 = relu((n00 * 0.5) + (n01 * -0.2)) #if then else
n12 = relu((n00 * -0.5) + (n01 * 0.1)) #if then else
o0 = (n11*1.0)+ (n12 * -1.0)
o1 = (n11*-1.0) + (n12 * 1)
# assertion(i0 <= i1 => o0 >= o1)
return o0, o1
|
(i0 * 1.0) + (i1* -1.0) > 0
true/ \false
n00_ =n00 .....
.......
/ \
# z3
i0 = z3.Real('i0')
i1 = z3.real('i1')
n00 = i0 * 1.0 # z3 knows that this would be i0 * 1.0
n00 = z3.If((i0 * 1.0) + (i1* -1.0)), n00_ = n00 , n00_ = 0)
o0_formula = ... # some large z3 formula
o1_formula = .... # some large z3 formula
assertion = i0 <= i1 => o0 >= o1
goal = Implies(z3.And(o0_formula, o1_formula), assertion)
z3.prove(goal)
i0 = 1.5
i1 = -2.0
n00 = (1.5 * 1.0) + (-2.0 * -1.0) = 1.5 + 2 = 3.5
n00 = relu(n00) = 3.5
n01 = (1.5 * 1.0) + (-2.0 * 1) = 1.5 - 2 = -0.5
n01 = relu(n01) = 0
n11 = relu((3.5 * 0.5) + (0 * -0.2) = .... ) =
n12 = ....
o0 = (n11 * 1.0) + (n12 * -1.0) = ...
o1 = ....
relu : def relu(v):
# return v if max(0, v) else 0
if v > 0:
return v
else:
return 0
Topics 2: Verification
- Static analysis
- compiling
- light-weight static analysis
- simpler problems
-
VERIFY PROGRAM CORRECTNESS (not light-weight, very heavy weight)
-
"Program testing are used to show the presence of bugs, but never to show their absence" Dijkstra 1972
-
Program Verification are used to show the ABSENCE of bugs, "but not its presence"
-
Static Analysis Techniques
- analyze some static representation of the program
- Source code (.c , .py)
- AST
- Bytecode (e.g., Java)
- LLVM (LLVM IR (intermediate representation))
- Fully Automated: "push-button" (no user intervention)
Static analysis / Verification tool
-
Inputs:
- (representation of the) program
- specifications (assertions, invariants, pre/post conditions)
-
Ideal / Perfect Verification tool:
- Correctness/Soundness: will not MISSCLASSIFY bugs (if the verification tool says the program has NO bug / SAFE => the program really has NO bug / SAFE).
- Completeness: (if the program has no BUG => the verification tool says the program has no BUG). Completeness more difficult to achieve.
- FAST (Terminates): does not run forever (ideally as efficient as possible)
Testing => Terminations (rquired), Completeness (semi-required), Correctness (meaning proving absense of errors -> not required)
Verification => Termination (required), Completeness (semi-required), Correctness (meaning proving absense of errors => required)
- How hard are these verification problems?
- Does this input program P free of
null ptrdereferencing ? - Does this program
Psatisfy some given assertions ? -
Does this program
Pterminate? -
UNDECIDABLE problems
- (Rice theorem): every non-trival questions about program reasoning is undecidable (in the general case).
Floyd-Hoare Logics / Axiomatic Semantics
- Hoare Tripple:
{P} S {Q} S: is a program (or a list of statements)P: is a formula that holds before the execution of S (precondition)Q: is a formula that holds after the execution of S (postcondition)- Read: assume P holds, if S successfully executes, then Q holds
- Precondition: constraints/formulae over the INPUTS
- WEAKEST (MOST GENERAL) PRECONDITION
- Postconditions: constraints/formulae over BOTH INPUTS and OUTPUTS
- STRONGEST (MOST SPECIFIC) POSTCONDITION
- Precondition: constraints/formulae over the INPUTS
- Partial vs Total Correctness
- Partial Correctness: you assume the program terminates (S successfully executed) <== we mostly deal with partial correctness
- Total Correctness: you require the program terminates
def div(x, y):
"""
performs r = x / y
"""
# P: x and y are numbers, y != 0, x and y are POSTIVE
#
# .... S
# Q? r is number , y*r == x (x = y * r + remainder),
return r
BC: O(Log(n))
WC: O(n^2)
python dd.py ../myowndirect/file.sh
Best case/Worst case : this means in terms of the number of tests (log(n) of any input, not just short input) Worst case: many did linear, not O(n^2) easy way to check: the number of lines, e.g., 10 O(n^2), around 100. log n : 6 times
Problems with running executable command lines
PA4: do by hand first (only 2 layers, can easily do by hand)
Floyd-Hoare Logics / Axiomatic Semantics
- Goal: to prove that a program
Sis correct with respect to a given preconditionPand postconditionQ. - Method: proving Hoare tripple
- Computing weakest precondition of
Swith respect toQ, i.e.,wp(S, Q)- If for every loop in
S, need to provide a loop invariant
- If for every loop in
- Form verification condition (vc)
P = > wp(S, Q)- If this vc is true, then the Hoare tripple is valid, i.e.,
Sis correct wrt toPandQ - Else, Hoare tripple is invalid but we cannot conclude that
Sis incorrect wrt toPandQ(it could be that we picked a weak loop invariant)
- If this vc is true, then the Hoare tripple is valid, i.e.,
Hoare Tripple: {P} S {Q}
S: is a program (a list of statements)P: is a formula that holds before the execution of S (precondition)Q: is a formula that holds after the execution of S (postcondition)- Read: assume P holds, if
Ssuccessfully executes, thenQholds - Partial vs Total Correctness
- Partial Correctness: you assume the program
Sterminates <== we mostly deal with partial correctness - Total Correctness: you need to check the program terminates
- Partial Correctness: you assume the program
Examples
# Valid Hoare triples (i.e., the Hoare triples are true)
{True} x := 5 {x >= 0} # this post cond is ok, but not strongest
{True} x := 5 {x ==4 or x == 5} # this post cond is ok, but not strongest
{True} x := 5 {x==5} # this post cond is the strongest
{x == y} x:= x + 3 { x == y + 3 }
{x > -1} x:= 2*x + 3 {x > 1}
{x==y} y = x {x==y}
{x==y} print("something") {x==y}
{x==y} pass {x==y}
{x==a} if x < 0: x = - x {x == |a|}
{True} if x < 3: x = 10 else: x = 20 {10 <= x <= 20}
{True} if x < 3: x = 10 else: x = 20 {x == 10 || x == 10}
{False} x := 3 {x == 8} # *valid* , because the precondition is False. Since the assumption does not hold, anything is possible and thus this is valid
{False} x := 3 {ANY FORMULA} # valid, similar reasoning, assumption does not hold so anything postcondition is OK
{x < 0} while(x!=0) x:= x - 1 {ANY FORMULA} # valid, similar reasoning, program does not terminate and therefore assumption does not hold, thus anything is possible. Note this is OK for partial correctness, but not total correctness.
# Invalid Hoare triples
{True} x := 5 {x > 6} # x ==5 does not imply x > 6
{x == 5} x += 2 {x < 7} # x == 7 does not imply x < 7
Strongest Postconditions
The strongest post condition is the post condition that is stronger than every other post conditions.
# Everyone postconditions below are valid (i.e., make the Hoare triple true)
# But the last one is the strongest (most preferred) as it captures the progarm most accurately
{x==5} x:=x*2 {true}
{x==5} x:=x*2 {x>0}
{x==5} x:=x*2 {x==10 or x ==5}
{x==5} x:=x*2 {x==10} <= strongest post condition
a
b
c
b => a,
b => c,
then b is the strongest postcondition (among a,b,c)
x=10 => x==10 or x= 5 YES, strongest among these 3
x=10 => x> 0 YES
x=10 => true YES # everything implies true, false implies anything
Weakest Precondition
{x==5 and y == 10} z:= x/y {z < 1}
{x < y and y > 0} z:= x/y {z < 1}
{y != 0 and x/y < 1} z:= x/y {z < 1}
foo(x,y):
# no assumpption on x,y => precondition == TRUE (weakest possible precondition)
# assume y != 0
# x < y
....
a
b
c
a=>b
c=>b
then b is the weakest (among a,b,c)
VERIFICATION USING HOARE Tripples and WEAKEST Preconditions
- Tony Hoare
- Quick sort
- null pointer (billion mistake)
- dining philosopher problem / monitor concept
-
...
-
To prove {P} S {Q} is valid, we check if P => WP(S, Q)
- WP: a function returning the weakest precondition allowing the execution of S to achieve Q
- ASSIGNMENT
- {y==7} x:=3 {x + y == 10}
- { y > -3 } x:=3 {x + y > 0}
wp(x:= E, Q) = Q[x/E]wp(x:=3 {x + y == 10}) = 3 + y == 10 => y == 7wp(x:=3, {x + y > 0}) = 3 + y > 0 => y > -3
- SKIP (PASS)
wp( SKIP, Q) = Q
- A list of statements (sequential statements)
wp(S1;S2 , Q) => wp(S1, wp(S2, Q))wp(x:=x+1 ; y := y*x , {y==2*z}) = wp(x:=x+1, wp(y:=y*x, {y==2*z})) = wp(x:=x+1, {y*x==2*z}) = {y*(x+1) = 2*z}
- Conditional statement
wp(if b then S1 else S2, {Q}) = b=> wp(S1,Q) and !b => wp(S2, Q)wp(if x > 0 then y :=x else y:= 0, {y > 0}) = x>0 => wp(y:=x, {y >0}) and x<=0 => wp(y:=0, {y>0})x > 0 => x > 0 and x <= 0 => 0 > 0=>(x <= 0 => False)a->b ~a or b => x > 0x > 0 => x > 0 and x > 0 => x > 0wp(if b then S1 else S2, {Q}) = x > 0
- Loop : While loop
wp(while b do S, {Q}) = ??-
x = 0 ; while (random(t,f)) x = x + 1;x =??
x = 0 ; while (x < 100)) x = x + 1;x =100 (because the loop is bounded by a finite number)- Loop invariant: captures the meaning of the loop (manually provided by you)
- property that holds when the loop entered
- is preserved after the loop body is executed (inductive loop invariant)
{N >= 0}
i = 0
# i<= N
while (i < N):
i = N
# i <= N # i < N OR i == N
# loop invs
# i < N # not a loop invariant because at first loop entrance, when N = 0 , i is NOT < N
# i >= 0 # YES , loop inv
# N >= 0 # YES, loop inv
# i <= N # YES, loop inv
# N >= -10
# N >= -11000
- WP for While loop
wp(while b do S, {Q}) = I and (I and b => wp(S,I) and (I and !b) =>Q)- We need to find/guess a loop I such that
- init case: I is true (right before entering the loop the first time)
- I and b => I : I is preserved after each loop body execution (inductive case)
- I and !b => q : if the loop terminates, the post condition holds
# WS
{N >= 0} # P
i = 0
# i<= N
while (i < N):
# i <= N {P'}
#i < N and i <= N => wp
# i < N and i <= N => true (= True, after simplification)
#wp(i := N, {i<=N}) = N <= N # True
# ....
i = N
# I <= N {Q'}
{ i == N} # Q
# 1. N >= 0
# 2. i <= N # chosen one
wp(while b do S, {Q}) = I and (I and b => wp(S,I) and (I and !b) =>Q)
- `wp(WS, { i == N}) =1. i <= N 2. (i <= N and i < N) => wp(i := N, i <=N) # i < N => N <= N => TRUE 3. (i <= N and !(i < N)) => i == N
Verification condition
-
The VC of the Hoare tripple {P} S {Q} is
P => wp(S, Q)(and if this is true, then the Hoare tripple holds, i.e., the program S is correct wrt to the specification P and Q) -
wp(i := 0, wp(WS, { i == N})) =
- 0 <= N
- (i <= N and i < N) => wp(i := N, i <=N) # i < N => True
-
(0 <= N and !(0 < N)) => 0 == N # True
0 >= N O = N => O == N -
N >= 0 => 0 <= N TRUE
IN-CLASS Exercise
{x <= 10} #P
while x != 10:
x := x + 1
{x == 10} #Q
{N >= 0} # P
# S starts
i = 0
while (i < N):
i = N
# S ends
{i == N} # Q
# loop inv i <= N
VC : P => wp(S, Q)
{N >= 0} => wp([i=0; while(i< N): i = N], {i == N}) => wp(i=0, wp(while .., {i==N}))
wp([S1,S2], Q) => wp(S1, wp(S2, Q))
{P} {F3} = wp (S1, F2) S1 {F2} = wp(S2, F1) S2 {F1} = wp (S3, Q) S3 {Q}
WP for While loop
- wp(while b do S, {Q}) = I and (I and b => wp(S,I) and (I and !b) =>Q)
- We need to find/guess a loop I such that
- init case: I is true (right before entering the loop the first time)
- I and b => I : I is preserved after each loop body execution (inductive case)
- I and !b => q : if the loop terminates, the post condition holds
wp(while (i < N) : i = N , {i == N}) =
1. I => i <= N
2. I and b => wp (S, I) => (i <= N and i < N) => wp (i=N, {i <= N}) => i < N => N <= N => i< N => N ==N
3. I and !b => Q => i<= N and i >= N => i == N
Revisiting Loop Invariants and Hoare Triples
{N >= 0} # P
# S starts
i = 0
while (i < N):
i = i + 1
# S ends
{i == N} # Q
Observe that this program is correct (it also terminates and at the end have
i == N. But we want to formally prove it using Hoare tripple.
Using a sufficiently strong loop invariant
- guess
I=i <= Nand reason that it is a loop invariant: - first time we enter the loop,
i<=Nholds because(i == 0 and N >= 0) => i <= N -
assume
i <= Nwhen we enter the loop (soi <= Nandi < N), then after executing the loop bodyi = i + 1, we still havei <= N. > Notice how the loop guardi < Nis crucial to establish this observation, because withouti < N, we can say that at the beginning of the loop we havei == Nand incrementiby one we would havei == N + 1, which does not preserve the invarianti <= N. -
computing
wp(i = 0; while[i <= N] i < N: i = i + 1, {i == N})using the loop invariantI = i <= Nyou just guess:wp(i = 0; while[i <= N] i < N: i = i + 1, {i == N}) = wp(i = 0, wp(while[i <= N] i < N: i = i + 1, {i == N})) # sequential rule of wp # let's comput the wp(while[i <= N] i < N: i = i + 1, {i == N}), which would have the 3 cases: 1. i <= N # I 2. (i <= N and i < N) ==> wp(i = i + 1, {i <= N}) ==> i + 1 <= N # assignment rule of wp ==> i <= N - 1 # simplify TRUE # simplify, because (i <= N and i < N) ==> i <= N - 1 (i,N are both integers) 3. (i <= N and !(i < N)) ==> i == N TRUE # simplified to TRUE because i <= N and i >= N implies i == N (i <= N and i >= N is just i == N). # so we have wp(while[i <= N] i < N: i = i + 1, {i == N}) = i <= N # (i <= N and TRUE and TRUE simplifies to i <= N) # continue with the rest wp(i = 0; while[i <= N] i < N: i = i + 1, {i == N}) = wp(i = 0, i <= N) = 0 <= N # assignment rule # so wp(i = 0; while[i <= N] i < N: i = i + 1, {i == N}) is 0 <= N - To check if the program
Sis correct wrt to givenPandQ, we check the verification conditionvc : P ==> wp(S, Q)N >= 0 ==> wp(i = 0; while[i <= N] i < N: i = i + 1, {i == N}) ==> 0 <= N TRUE #so Hoare tripple is valid and S is correct wrt to P and Q
Thus, by using this loop invariant
i <= N, we was able to formally prove the program.
using a loop invariant that is not sufficiently strong
- guess
I=N >= 0and reason that it is a loop invariant: - first time we enter the loop,
N >= 0holds because(i == 0 and N >= 0) ==> N >= 0 -
assume
N >= 0when we enter the loop (soN >= 0andi < N), then after executing the loop bodyi = i + 1, we still haveN >= 0. > it's pretty to reason aboutN >= 0here because the loop body never changedNso whatever holds aboutNbefore will also holds after the loop body. -
computing
wp(i = 0; while[N >= 0] i < N: i = i + 1, {i == N})using the loop invariantI = N >= 0you just guess:wp(i = 0; while[N >= 0] i < N: i = i + 1, {i == N}) = wp(i = 0, wp(while[N >= 0] i < N: i = i + 1, {i == N})) # sequential rule of wp # let's comput the wp(while[i <= N] i < N: i = i + 1, {i == N}), which would have the 3 cases: 1. N >= 0 # I 2. (N >= 0 and i < N) ==> wp(i = i + 1, {N >= 0}) ==> N >= 0 # assignment rule of wp, no i in N >= 0 s TRUE # simplify, because (N >= 0 and i < N) ==> N >= 0 3. (N >= 0 and !(i < N)) ==> i == N (N >= 0 and i >= N) ==> i == N FALSE # we could have i = 2, N =1 # so we have wp(while[N >= 0] i < N: i = i + 1, {i == N}) = FALSE # (i <= N and TRUE and FALSE simplifies FALSE) # continue with the rest wp(i = 0; while[i <= N] i < N: i = i + 1, {i == N}) = wp(i = 0, FALSE) = FALSE # assignment rule # so wp(i = 0; while[N >= 0] i < N: i = i + 1, {i == N}) is FALSE - To check if the program
Sis correct wrt to givenPandQ, we check the verification conditionvc : P ==> wp(S, Q)N >= 0 => wp(i = 0; while[N >= 0] i < N: i = i + 1, {i == N}) N >= 0 => FALSE FALSE # we could have N = 1
Thus, by using this loop invariant
N >= 0, we were NOT able to formally prove that this program is correct wrt to the given specificationPandQ.
Two main points from this example: 1. Not able to prove does not mean the program is wrong. It just means that we can't show it is correct 2. Choosing sufficiently strong loop invariant is important
A More Complicated Example
def do_something_1(A, B):
assert A >= 0 and B >= 0 # P
# given I = A^B = x^y * z
x = A
y = B
z = 1
while True:
# loop invariant: A**B == x ** y * z
if not (y != 0):
break
if y % 2 == 1: #odd
y = y - 1
z = x * z
else:
x = x * x
y = y // 2
assert z == A**B # Q , this program computes A^B (assumming A and B are non-neg)
Prove
do_something_1is correct wrt the givenPandQusing the supplied loop invariantA**B == x ** y * z
-
does
Ihold when we enter the loop ?YES, because
A >= 0 and B >= 0 and x==A and y == B and z == 1impliesA**B == x ** y * z, simplified toA**B = A**B*1, simplified TRUE becauseA**B = A**B -
when this loop (i.e., the loop invariant
I) exits, do we get the post conditionQ?YES,
A**B == x ** y * z and y == 0 => z == A**B, simplified toA**B == x**0*z, simplified toA**B = z => z == A**B, simplified to TRUE -
assume I holds when enter the loop, show that the loop body preserves it at the end.
- wp(if(g).....) is splitted into 2 cases : (i) when `g` holds and (ii) when `g` does not hold 1. A**B == x ** y * z and y != 0 and y%2 == 1` => wp(y = y - 1; z = x * z, {A**B == x ** y * z }) => wp(y = y - 1, {A**B = x ** y * (x*z)}) => A**B = x ** (y-1) * (x*z) => A**B = x**y * z # x^(y-1) * x = x ^ y TRUE # loop inv is preserved in this then branch 2. A**B == x ** y * z and y != 0 and y%2 != 1 => wp(x = x * x ; y = y // 2, {A**B == x**y * z}) => wp(x = x * x; {A**B == x**(y//2) * z}) # y // 2 when y == even is the same as y/2 => wp(x = x * x; {A**B == x**(y/2) * z}) => A**B == (x*x)**(y/2) * z => A**B = x**y * z #(x^2)^(y/2) = x^y TRUE # loop inv is preserved in this else branch
Thus, this program is correct wrt to the given P,Q using the provided invariant I. Note that for this program we can also show that the program terminates and hence achieve total correctness (instead of just partial correctness).
In-class Assignment
def do_something_2(A):
assert A >= 0 # P
x = 1
y = A
z = 1
while True:
# loop invariant I: 2**A == (x+z) * 2**(y-1)
if not (y != 0 or z != x):
break
if z == 0:
y = y - 1
z = x
else:
x = x + 1
z = z - 1
assert x == 2 ** A # Q
do_something_2 is correct wrt to the given specifications P and Q using the provided loop invariant I. More specifically, do the following (see example for do_something_1 in class notes, you do not need to follow this exact order)
1. Show I holds when the loop is entered the first time
2. Show when loop exits, I and the negation of the loop guard implies Q
3. Show that assuming I holds at the loop entrance, I will also hold after the loop body is executed.
Abstract Interpretation
- Axiomatic semantics, i.e., Hoare logic,
- need to provide loop invariants, a difficult and error-prone process.
- not an automatic, push-button approach (but still powerful and used in many verification tools, e.g., Microsoft Dafny)
-
Also relies on checking validity of verification conditions
- For complex programs, can be very expensive and in many cases not feasible
-
Abstract interpretation
- Also a verification / static analysis approach
-
Does not require loop invariants and expensive formula checkings.
-
Abstraction
x = 1349 # x is a pos number y = 134234 # y is a pos
z = x * y # multiplication of 2 pos nubmers => pos numbers
assert(z >= 0)
Example: Abstract Domain: Zero, Odd, Even (over natural numbers)
- Map from concrete natural numbers to either {0, odd, even}
- Examples:
5 -> odd , 4 -> even , 0 -> 0
Abstract Transformer
- 5 + 2 = 7 => but in the Zero/Odd/Even domain, this becomes
Odd + Even = Odd - Addition (+):
0 + odd -> odd,even + odd -> oddodd + odd -> odd
| + | 0 | odd | even |
|---|---|---|---|
| 0 | 0 | odd | even |
| odd | 0 | even | odd |
| even | 0 | odd | even |
- Greater than (>):
0 > 0 -> f,0 > odd -> false,even > even -> true/false(don't know or T)
| > | 0 | odd | even |
|---|---|---|---|
| 0 | f | f | f |
| odd | t | t/f | t/f |
| even | t | t/f | t/f |
- Intger division (//)
4//2 = 2 , 5 // 2 = 2
| // | 0 | odd | even |
|---|---|---|---|
| 0 | ?? | 0 | 0 |
| odd | ?? | T (top) | T |
| even | ?? | T | T |
7//3 = 2 E 9//3 = 3 O 1//3 = 0 O
5//2
3//2 = 1
- Multiplication (*): 0 * odd -> 0 , odd * odd -> odd , even * odd -> even
Example
def mult(A,B):
# P = {A >= 0 and B >= 0}
x = A
y = B
z = 0
# L1
while
# L2
if !(x > 0): # enter loop when x > 0 , exit when x <= 0
break
if x % 2 == 1: #x is odd
z = z + y
x = x // 2
y = y * 2
# L3
# L4 : find abstract values of x,y,z
return z
The mult program
- multiplies two natural numbers A and B
- goal: find the values of \(x, y, z\) using the abstract domains {Zero, Odd, Even} at location L4 (the end of the program)
Enumerate all possible cases for the inputs A, B over the values Zero, Odd, Even
Case 1: when
A=odd,B=odd
| loc | x | y | z | |
|---|---|---|---|---|
| init | L1 | O | O | 0 |
| loop entrance | L2 | O | O | 0 |
| loop exit (not possible) | L4 | F | F | F |
| loop iter 1 (x>0) | O | F | F | |
| c1: when x is odd | L3 | T | E | O |
| c2: when x is NOT odd (not possible) | L3 | F | F | F |
| union the 2 cases | L3 | T | E | O |
| loop entrance | L2 | T | E | O |
| loop exit (possible) | L4 | 0 | E | O |
| loop iter 2 (x>0) | E/O | E | O | |
| c1: when x is odd | L3 | T | E | O |
| c2: when x is NOT odd (possible) | L3 | O/E | E | O |
| union the 2 cases | L3 | T | E | O |
| loop entrance | L2 | T | E | O |
| union all exits | L4 | 0 | E | O |
Case 2 : A odd, B even
In-class Assignment: do the case when A = odd and B = even (due Tues at 10:59 AM)
Case 3 : A 0 , B even ...
Latice Theory (Galois Connection)
anything (T)
/
rational
/
int
/ \
/ \
even-int nonneg
\ / \
\ > 1 0--9
\ \ / \
\ \ / {2,5,0}
\ \ / /
2 # very informative
|
F # very strong information
End of class R 11/5
Example 1
//@requires A >= 0 && B >= 0;
int mod(int A, int B) {
int Q = 0;
int R = A;
while(1){
if !(R >= B) break;
R = R - B;
Q = Q + 1;
}
return R;
Odd/Even Domain v={O,E,0}
//@requires A >= 0 && B >= 0;
int mod(int A, int B) {
// {A:T, B:T}
int Q = 0;
// {A:T, B:T, Q:0}
int R = A;
// {A:T, B:T, Q:0, R:T} # R = A => R:T
while(1){
// {A:T, B:T, Q:0, R:T}
if !(R >= B) break;
// {A:T, B:T, Q:0, R:T}
R = R - B;
// {A:T, B:T, Q:0, R:T}
Q = Q + 1;
// {A:T, B:T, Q:O/E, R:T}
}
// {A:T, B:T, Q:0/O/E=T, R:T}
return R;
End of class T 11/10